Защита компонентов
Допустим, программа должна обрабатывать два компонента- связанный список структур NODE и двоичное дсрсво структур BRANCH. Представим также, что у Вас есть два файла исходного кода: LnkLst.cpp, содержащий функции для обработки связанного списка, и BinTree.cpp с функциями для обработки двоичного дерева.
Если структуры NODE и BRANCH хранятся в одной куче, то она может выглядеть примерно так, как показано на рис. 18-1.
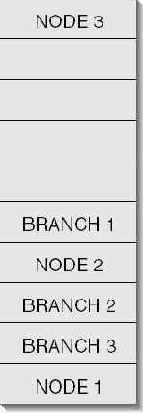
Рис. 18-1. Единая куча, в которой размещены структуры NODE и BRANCH
Теперь предположим, что в коде, обрабатывающем связанный список, "сидит жучок", который приводит к случайной перезаписи 8 байтов после NODE 1. А это в свою очередь влечет порчу данных в BRANCH 3. Впоследствии, когда код из файла BinTree.cpp пытается "пройти" по двоичному дереву, происходит сбой из-за того, что часть данных в памяти испорчена. Можно подумать, что ошибка возникает из-за "жучка" в коде двоичного дерева, тогда как на самом деле он — в коде связанного списка. А поскольку разные типы объектов смешаны в одну кучу (в прямом и переносном смысле), то отловить "жучков" в коде становится гораздо труднее.
Создав же две отдельные кучи — одну для NODE, другую для BRANCH, — Вы локализуете место возникновения ошибки. И тогда "жучок" в коде связанного списка не испортит целостности двоичного дерева, и наоборот. Конечно, всегда остается вероятность такой фатальной ошибки в коде, которая приведет к записи данных в постороннюю кучу, но это случается значительно реже.
